728x90

1. 슈퍼 / 서브 타입 데이터 모델의 변환타입?
- One To One Type
- 슈퍼타입과 서브타입을 개별 테이블로 도출한다.
- 테이블의 수가 많아서 조인이 많이 발생하고 관리가 어렵다.
- Plus Type
- 슈퍼타입과 서브타입 테이블로 도출한다.
- 조인이 발생하고 관리가 어렵다.
- 슈퍼타입과 서브타입 테이블로 도출한다.
- Single Type
- 슈퍼타입, 서브타입을 하나의 테이블로 도출하는 것이다.
- 조인성능이 좋고 관리가 편리하지만, I / O성능이 나쁘다.
- 슈퍼타입, 서브타입을 하나의 테이블로 도출하는 것이다.
2. 데이터베이스 모델링의 순서?
- 데이터 모델링을 할 때 정규화를 정확하게 수행
- 데이터베이스 용량산정 수행
- 데이터베이스에 발생되는 트랜잭션 유형 파악
- 용량과 트랜잭션의 유형에 따라 반정규화 수행
- 이력모델의 조정, PK / FK조정, 슈퍼타입 / 서브타입 조정 수행
- 성능관점에서 데이터 모델 검증
3. 데이터 모델링에서 주식별자를 도출하는 기준?
- 해당 업무에서 자주 이용되는 속성을 주식별자로 정의한다.
- 명칭, 내역등과 같이 이름으로 기술되는 것들은 가능하면 주식별자로 지정하지 않는다.
- 복합으로 주식별자를 구성할 경우 너무 많은 속성이 포함되지 않도록 한다.
4. SQL 집계함수?
- ROLLUP
- 소 그룹 간의 합계를 계산하는 함수이다. ROLLUP을 사용하면 GROUP BY로 묶은 각각의 소그룹의 합계와 전체 합계를 모두 구할 수 있다.

- CUBE
- 항목들 간의 다차원적인 소계를 계산한다. ROLLUP과 달리 GROUP BY절에 명시한 모든 컬럼에 대해 소그룹 합계를 계산해 준다.
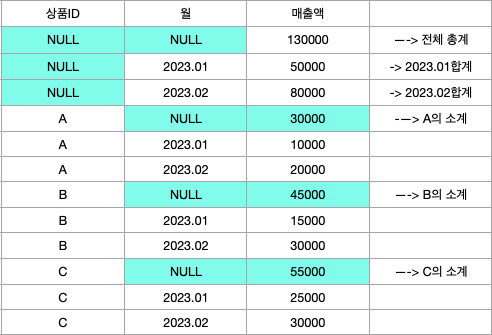
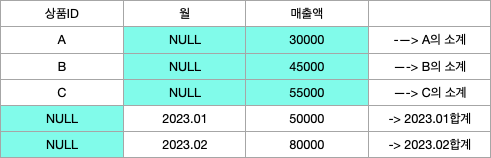
- GROUPING SETS
- 특정 항목에 대한 소계를 계산하는 함수이다.
5. SQL 실행 결과?

- CONNECT BY 계층형 조회 PRIOR가 없는 쪽에서 -> PRIOR가 있는 쪽으로
- 처리순서는
- Start with
- Connect by
- Where
- Start with
- 위의 처리 순서를 SQL문에 대입하면
- START WITH EMPNO = 3부터 시작해서
-> EMPNO가 3인 행부터 시작 - CONNECT BY EMPNO = PRIOR MANAGER 가 실행돼서
-> EMPNO가 3인 행의 MANAGER값인 2와 같은 EMPNO를 검색한다.
-> 그다음도 마찬가지로 EMPNO가 2인 행인 MANAGER값 1과 같은 EMPNO를 검색한다. - WHERE EMPNO <> 3
-> EMPNO가 3인 행 제외한다.
- START WITH EMPNO = 3부터 시작해서
- 따라서 출력값은 2건이다.
6. 설명이 틀린 것은?
1) RANK() OVER(PARTITION BY JOB ORDER BY 급여 DESC) JOB_RANK
-> #직업별 급여가 높은 순서대로 부여되고 동일한 순위는 동일한 값이 부여된다.
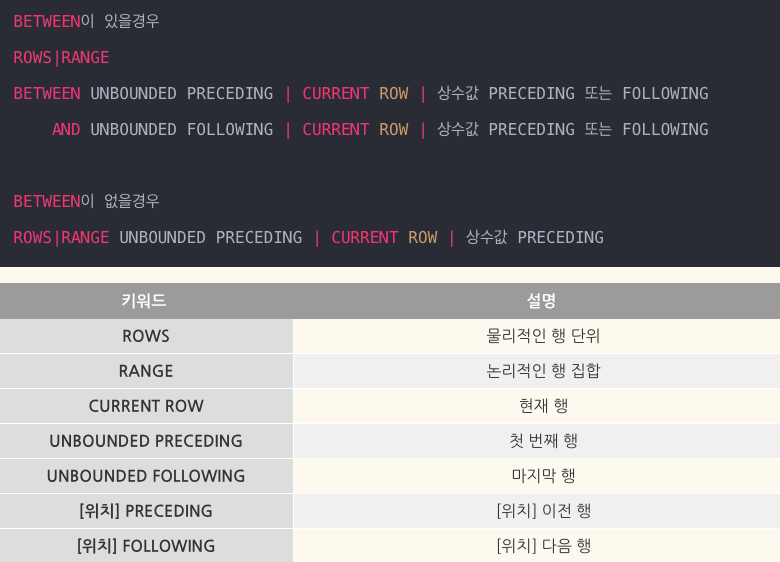
2) SUM(급여) OVER(PARTITION BY MGR ORDER BY 급여 RANGE UNBOUNDED PRECEDING)
-> #RANGE는 논리적 주소에 의한 행 집합을 의미하고 MGR별 현재 행부터 파티션 내 첫 번째 행까지 급여의 합계를 계산한다.
3) AVG(급여) OVER(PARTITION BY MGR ORDER BY 날짜 ROWS BETWEEN 1 PRECEDING AND 1 FOLLOWING))
-> #각 MGR 별로 앞의 한건, 현재 행, 뒤의 한건 사이에서 급여의 평균을 계산한다.
4) COUNT(*) OVER(ORDER BY 급여) RANGE BETWEEN 10 PRECEDING AND 300 FOLLOWING)
-> #급여를 기준으로 현재 행에서의 급여의 10에서 300 사이의 급여를 가지는 행의 수를 COUNT
3. MGR별로 급여의 평균을 계산하기 전에 날짜를 기준으로 정렬을 수행한 다음에 급여의 평균을 계산한다. 즉, 각 MGR 파티션 내에서 날
짜 기준으로 정렬을 수행했을 때, 파티션 내에서 앞의 한 건, 현재 행 뒤의 한 건 사이 급여의 평균을 계산한다.
- 윈도우절은 ROWS or RANGE 둘 중 하나를 선택하고 BETWEEN도 선택적으로 사용해서 결과에 대한 범위를 지정할 수 있다.
7. PL / SQL의 특징?
- PL / SQL은 Block구조로 되어있어 각 기능별로 모듈화가 가능하다.
- 변수, 상수 등을 선언하여 SQL문장 간 값을 교환한다.
- IF, LOOP 등의 절차형 언어를 사용하여 절차적인 프로그램이 가능하도록 한다.
- DBMS 정의 에러나 사용자 정의 에러를 정의하여 사용할 수 있다.
- PL / SQL은 Oracle에 내장되어 있으므로 Oracle과 PL / SQL을 지원하는 어떤 서버로도 프로그램을 옮길 수 있다.
- PL / SQL은 응용 프로그램의 성능을 향상시킨다.
- PL / SQL은 여러 SQL문장을 Block으로 묶고 한 번에 Block전부를 서버로 보내기 때문에 통신량을 줄일 수 있다.
8. SQL문이 올바른 것은?

- '%'나 '_'등과 같은 특수문자를 검색하기 위해서는 ESCAPE를 사용한다.
- SELECT * FROM TEST WHERE NAME LIKE '%_%';로 검색하면 '_'문자가 포함된 값을 가져오는 게 아니라 모든 행이 출력된다.
- 특수 구문을 사용하지 않으면 % 또는 _와 같은 특수 문자가 포함된 문자열 열에 대해 LIKE검색을 사용할 수 없다.
- SELECT * FROM TEST WHERE NAME LIKE '%@_%' ESCAPE '@';
LIKE 연산으로 '%'나 '_'등과 같은 특수문자를 검색하기 위해서는 위와 같이 ESCAPE를 사용해줘야 한다.
위의 쿼리에서는 @를 사용했지만 아무 특수문자나 사용해도 결과는 같다.
9. SQL에서 ORDER BY로 사용할 수 없는 것?

- 문제의 SQL문은 SELECT구에 JOB, ROWCNT 두 개의 컬럼이 있다.
10. SQL완성하기

- NULL 값이 마지막에 정렬되었다. 따라서 NULLS LAST로 정렬하면 된다.
- NULLS FIRST : 정렬하고자 하는 NULL 데이터들을 데이터 앞에 나오게 한다.
- NULLS LAST : 정렬하고자 하는 NULL 데이터들을 데이터 뒤에 나오게 한다.
한번 풀어봤던 거라 수월하게 풀렸다.
틀렸던 건 다시 한번 보면서 머릿속으로!
'WorkHard > 자격증' 카테고리의 다른 글
| [SQLD 개발자] 기출문제 공부(39회) (0) | 2023.03.18 |
|---|---|
| [SQLD 개발자] 기출문제 공부(38회) (0) | 2023.03.18 |
| [SQLD 개발자] 기출문제 공부(33회) (0) | 2023.03.15 |
| [SQLD 개발자] 기출문제 공부(33회) (1) | 2023.03.14 |
| [SQLD 개발자] 기출문제 공부(33회) (0) | 2023.03.14 |