728x90

1. Entity내에서 속성에 대한 데이터 타입과 크기 그리고 제약사항을 지정하는 것?
- 도메인!
2. 반정규화에 대한 설명?
- 데이터를 조회할 때 디스크의 I/O양이 많아서 성능이 저하되거나 경로가 너무 멀어 조인으로 인한 성능저하가 예상될 때 수행한다.
- 컬럼을 계산하여 읽을 때 성능이 저하될 것이 예상되는 경우 수행한다.
- 반정규화를 적용할 때는 기본적으로 데이터 무결성이 깨질 가능성이 많이 있으므로 반드시 데이터 무결성을 보장할 수 있는 방법을 고려해야 한다.
3. 물리적인 스키마 설계를 하기 전 단계는?
- 논리적 모델링
4. 반정규화 대상인 것은?
- 자주 사용되는 테이블에 접근하는 프로세스의 수가 많고 항상 일정한 범위만을 조회하는 경우(빈도수)
- 테이블에 대량의 데이터가 있고 대량의 데이터 범위를 자주 처리하는 경우에 처리범위를 일정하게 줄이지 않으면 성능을 보장할 수 없는 경우(대량범위)
- 통계성 프로세스에 의해 통계 정보를 필요로 할 때 별도의 통계 테이블을 생성해야 하는 경우(통계처리)
5. 분산 데이터베이스의 특징?
- 분산 DB : 논리적으로 같은 시스템, 물리적 분산, 데이터 무결성을 해침
- 분할 투명성 : 분할되서 여러군데 저장
- 위치 투명성 : 저장장소 명시가 불필요함, 데이터베이스의 실제 위치를 알 필요없이 단지 데이터베이스의 논리적인 명칭만으로 엑세스 할 수 있다.
- 지역사성 투명성 : 지역 DBSM와 물리적 DB사이 Mapping을 보장한다.
- 중복 투명성 : 데이터가 여러 곳에 중복되어 있더라고 사용자는 마치 하나의 데이터만 존재하는 것처럼 사용 가능하다.
- 장애 투명성 : 트랜젝션, DBMS, 네트워크, 컴퓨터 장애에도 트랜잭션을 정확하게 처리한다.
- 병행 투명성 : 다수의 트랜잭션이 동시에 실행되더라도 그 결과는 영향을 받지 않는다.
6. 오류가 발생하는 SQL문?
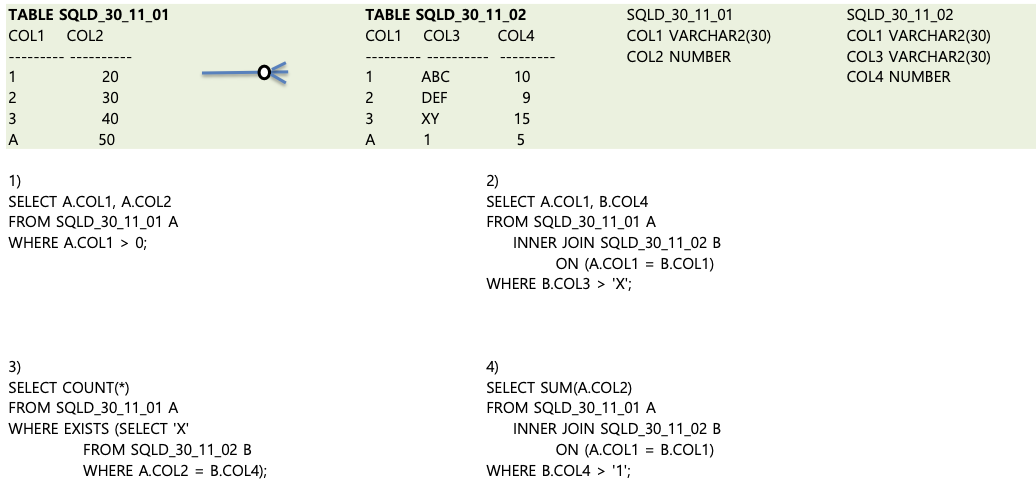
- COL1은 VARCHAR, 가변 문자열인데 A.COL > 0;에서 비교연산 하려해서 오류가 발생한다.
- 따라서 1번은 불가능하다.
- FROM A테이블에서 INNER JOIN함으로써 같은것만 남긴다.(A.COL1 = B.COL1이니 다 남는다.) WHERE B.COL3 > 'X'; 는 문자열 연산이다. X문자열보다 큰것만 남긴다.(A~C, D~F는 X보다 작고, XY는 X가 동일하고 알파벳이 추가되어있으니 선택된다. )
- 따라서 2번은 (3, XY, 15)가 선택된다.
- FROM A테이블을 선택한다. EXISTS로 존재여부를 찾고, B테이블로 설정하고, A.COL2 = B.COL4인데 같은것이 없다.
- SELECT 'X'는 무시해도 괜찮다.
- 따라서 3번은 NULL을 출력한다.
- 2번과 같이 INNER JOIN으로 A, B테이블 모두 선택한다. B.COL1 데이터와 문자 1의 비교연산이다. 문자가 유요한 숫자형태이기 때문에 숫자로 형변환하서 비교연산을 진행한다.
7. 오류가 발생하는 SQL문?
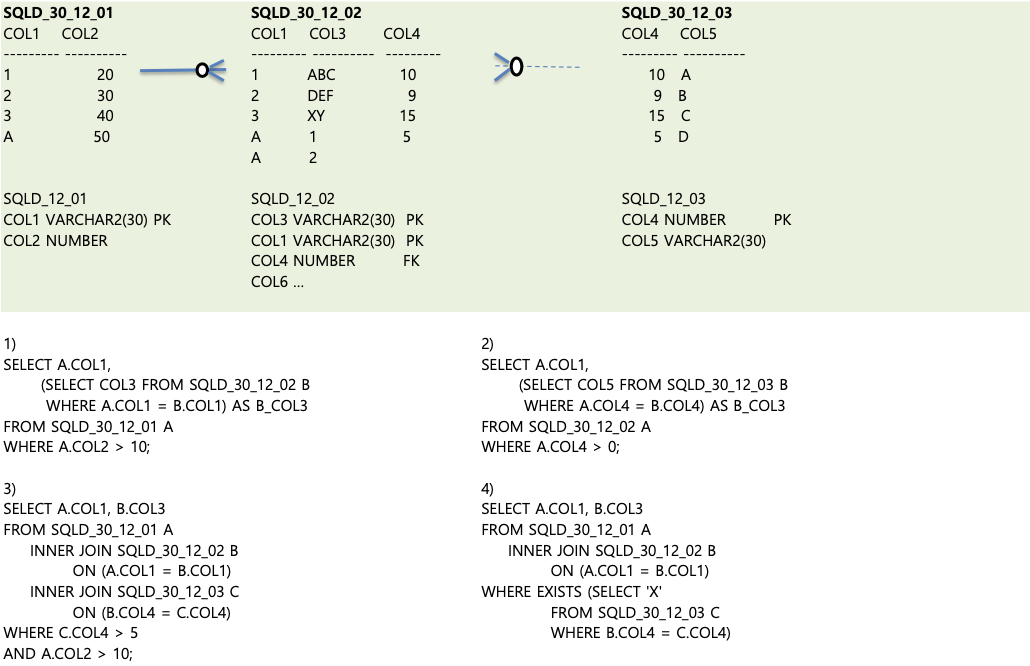
- A테이블 선택하고 A.COL2 > 10; 이니까 A전체 선택한다. A.COL1 = B.COL1에서 A가 2개 중복되서 오류가 난다.
8. 빈칸에 들어갈 내용?

- JOB_ID에 대한 합과, 총 합을 구하기 때문에 ROLLUP(JOB_ID, MANAGER_ID)를 사용한다. 인수 순서를 바꾸면 값이 달라지니까 인수 순서를 바꾸면 안된다.
- CUBE는 JOB_ID 합, MANAGER_ID 합, 총 합을 다 구한다.
- GROUPING SET은 합이 없다.
9. SQL 결과?

- COL1은 A, COL2는 50인 값 찾기, 따라서 답은 1개
10. SQL 결과?

- 표를 선택하고, COL1 = A OR COL1 = X OR COL1 = NULL인것을 찾는다
- (X, 30), (A, 40), (A, 50)이고 NULL은 넣는다고 뽑는게 아니다.
- 따라서 30 + 40 + 50 = 120이다.
11. 실행계획에 대한 SQL 수행 순서?

- 5번이 안쪽이지만 위에 TABLE ACCESS(FULL)이 있다.
- 3번과 4번은 같은위치니까 3 -> 4 번 순서이다.
- 여기서 5번이 제일 먼저지만 3번을 우선 넣어준것이다.(3 -> 5 -> 4)
- 7번이 더 안쪽이지만 2번 아래에 3~5번 계획이 있었으니, 계획을 수행하고 2번수행 마무리를하고 7번을 수행한다.(3 -> 5 -> 4 -> 2 -> 7)
- 그리고 6번을 수행하고 1번, 0번순으로 수행한다.
- 따라서 (3 -> 5 -> 4 -> 2 -> 7 -> 6 -> 1 -> 0)순서이다.
12. 수행결과로 올바른 것?

- 표를 선택하고, WHERE 1 = 2는 공집합이라는 뜻이다.
- COUNT(*) = 0 (공집합이니까 0이된다.)
- NVL -> COUNT(*) IS NULL이면 9999, 아니면 COUNT(*)을 반환한다.
- NVL(값, 지정값) : 값이 NULL인 경우, 지정값을 출력하고 IS NULL인 경우 값을 출력한다.
- 따라서 0이 정답이다.
13. SQL문이 순서대로 수행되었을 때 최종 결과값?

- SAVEPOINT 이름이 같으면 나중에 저장한 값으로 ROLLBACK을 한다.
- 따라서 COL1 -> 1, 2 / COL1 -> 1, 4 / COL1 -> 1, 4, 3이다.
- MAX(COL1) 즉, 최댓값을 출력하는 거니까 4이다.
14. Trigger에 대한 설명?
- DELETE ON TRIGGER : OLD는 삭제 전 데이터, NEW는 삭제 후 데이터
- UPDATE TRIGGER : OLD는 수정 전 데이터, NEW는 수정 후 데이터
- 특정 테이블에 DML문이 수행되었을 때 자동으로 동작한다.
- TRIGGER는 DB자체에 저장하고 테이블, 뷰에도 저장가능하다.
15. 결과가 NULL이 아닌것?
- SELECT COALESCE ('AB', 'BC', 'CD') FROM DUAL;
- NULL이 아닌 최초값 'AB'를 출력한다.
- SELECT CASE 'AB' WHEN 'BC' THEN 'CD' END FROM DUAL;
- If문과 같다. AB = BC면 CD출력 -> 아니니까 NULL출력
- SELECT DECODE ('AB', 'CD', 'DE') FROM DUAL;
- AB = CD면 DE를 출력, 아니면 NULL출력
- SELECT NULLIF('AB', 'AB') FROM DUAL;
- AB = AB면 NULL 출력, 아니면 AB출력
16. DML, DCL, DDL TCL?
- DML : CREATE, DROP, MODIFY(오라클에서), ALTER(SQL서버에서)
- DCL : SELECT, INSERT, DELETE, UPDATE
- DDL : GRANK, REVOKE
- TCL : COMMIT, ROLLBACK
17. 항상 동일한 결과를 출력하는 SQL은?

- ROWNUM : 상위부터 N개 추출
- TOP : ORDER BY가 있으면 정렬 후 상위 N개 추출
- 문제를 보면 HR.EMPLOYEES에서 SALARY로 정렬하고 위에서 10개 추출한다.
- HR.EMPLOYEES를 선택하고 위에서 10개 추출한후 SALARY로 정렬한다.
- HR.EMPLOYEES를 선택하고 SALARY로 정렬 후 상위 10개를 뽑는데, 같은 SALARY를 받는 사람을 같이 출력한다.
- HR.EMPLOYEES를 선택하고 FIRST_NAME, JOB_ID를 선택해서 ROWNUM이 먼저 실행된다.
- HR.EMPLOYEES를 선택하고 FIRST_NAME, JOB_ID를 선택해서 SALARY로 정렬 후 상위 10개를 뽑는다.
18. SQL 빈칸에 들어갈 말은?

- HR.EMPLOYEES에서 출발해서 START WITH () 인데 첫번째에 MANAGER_ID가 비어있으므로 "MANAGER_ID IS NULL"이 들어가야 한다.
- CONNECT BY PRIOR은 자식노드 = 부모노드, 이전 자식노드 값 = 현재 부모노드 값이므로 EMPLOYEE_ID = MANAGER_ID이다.
19. SQL Set Qperation에서 중복 제거를 위한 정렬 작업?
- 합집합 : UNION
- 중복허용 합집합 : UNION ALL(빠르다.)
- 교집합 :INTERSECT
- 차집합 : MINUS
- Nested Loop Join : 랜덤으로 엑세스 된다, 대용량 Sort작업에 유리하다
- Sort Merge Join : 등가, 비등가 조인이 가능하다, 조인키 기준 정렬한다, 각 테이블 정렬 후 조인한다.
- Hash Join : 등가 조인만 가능하다, 함수를 처리한다, 선행 테이블이 작다, 별도의 저장공간이 필요하다, 인덱스가 없으면 유리하다, 대량배치작업에 유리하다.
20. ERD에서 모든 회원의 총 주문금액을 구하는 SQL중 잘못된 SQL은?
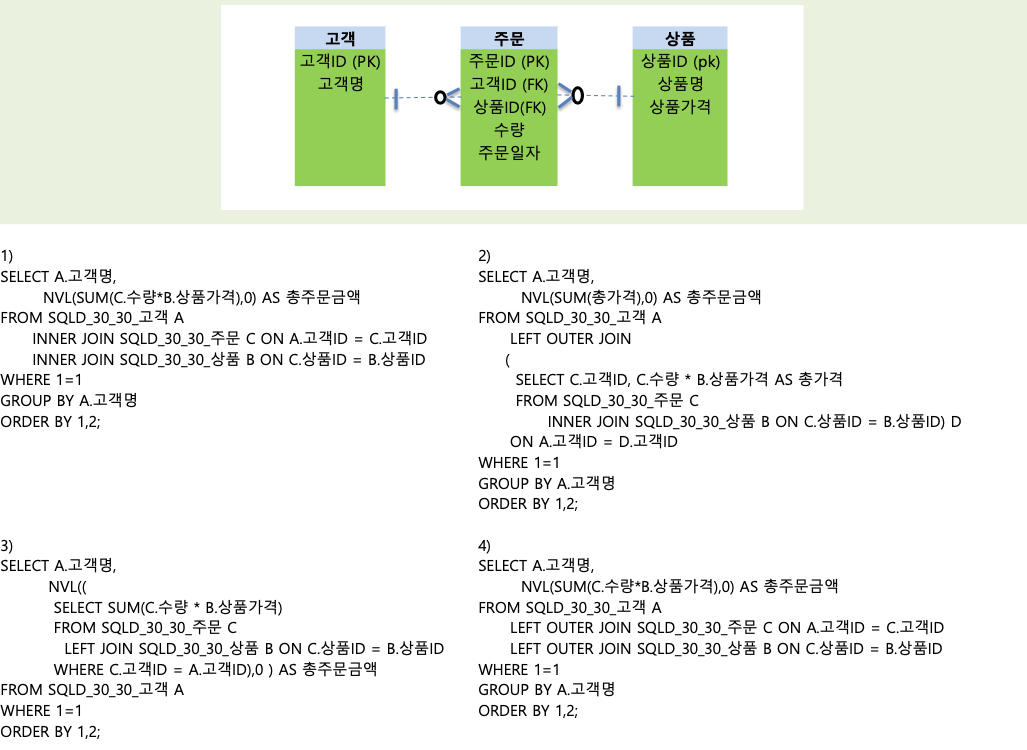
- INNER JOIN SQLD_30_30_주문 C ON A.고객ID = C.고객ID
INNER JOIN SQLD_30_30_상품 B ON C.상품ID = B.상품ID
에서보면 모든 고객의 총 주문금액인데 INNER JOIN을 하면서 서로 겹치는 것만 선택된다.
이에, 주문한 고객ID만 남아서 총주문금액을 고르는 것엔 적합하지 않다.
'WorkHard > 자격증' 카테고리의 다른 글
| [SQLD 개발자] 기출문제 공부(34회) (0) | 2023.03.03 |
|---|---|
| [SQLD 개발자] 기출문제 공부(30회) (0) | 2023.03.03 |
| [SQLD 개발자] 기출문제 공부(21회) (0) | 2023.03.01 |
| [SQLD 개발자] 기출문제 공부(21회) (0) | 2023.02.28 |
| [SQLD 개발자] 기출문제 공부(21회) (0) | 2023.02.27 |